Why GPT Image 2 Blocks Your Prompts (and What to Do About It)
TL;DR: GPT Image 2's three block messages all originate from OpenAI's serving stack, not from ChatGPT itself. Type 1 is a prompt-level filter that fires before generation. Type 2 and Type 3 are a probabilistic post-generation similarity classifier — the same prompt can block once and pass the next time, which we verified end-to-end on 10 copyrighted IPs. Your three real options when you hit a block are retry, rewrite, or switch to a model that doesn't ship with OpenAI's similarity audit.
If you generate images in ChatGPT with GPT Image 2, sooner or later you will hit one of three block messages. They read slightly differently, they trigger at different stages of the pipeline, and they are almost never explained properly. This post is a mechanical walkthrough: what each message means, where in the generation pipeline it actually comes from, what a 10-IP copyright test showed us, and what you can realistically do when you hit one.
These blocks are enforced entirely on OpenAI's side — not by the ChatGPT UI, not by any particular subscription tier, and not by any client-side setting you can toggle. They happen at different points inside OpenAI's own serving stack, and the error text alone doesn't tell you which stage blocked you, why it was flagged, or whether retrying will help. That's what the rest of this article is for.
By the end you'll know:
- Exactly which pipeline stage produces each of the three block messages
- Why GPT Image 2 can "think about" your prompt for 35 seconds and then refuse to return the image
- Which copyrighted characters actually get blocked in practice (and why the result is not deterministic)
- What to do when you hit a block — retry, rewrite, or switch models
What do GPT Image 2's block messages actually mean?
The three messages are variants of two underlying block types: a pre-generation prompt filter and a post-generation image-similarity filter. Both live inside OpenAI's serving stack — ChatGPT is just the surface that displays their verdict.
Here are the three messages you will run into, copied verbatim from real generations:
Type 1 — Prompt-level block: We're so sorry, but the prompt may violate OpenAI's guardrails around nudity, sexuality, or erotic content.
Type 2 — Post-generation similarity block: We're so sorry, but the image we created may violate our guardrails concerning similarity to third-party content. If you think we got it wrong, please retry or edit your prompt.
Type 3 — Post-generation generic block: We're so sorry, but the image we created may violate our content policies. If you think we got it wrong, please retry or edit your prompt.
Type 1 fires before the image is generated. The model's safety layer reads your prompt, decides it trips the sexual-content filter, and refuses to start the generation job at all. You'll notice this one returns very quickly — usually within a few seconds — because nothing has been drawn yet.
Type 2 and Type 3 are the interesting ones. They fire after the model has already generated the image. The wording differs ("similarity to third-party content" vs. the more generic "may violate our content policies") but the mechanism is the same: the image is produced, then handed to a separate content-audit step, and rejected before it's returned to the caller. Type 2 is the specific branch for "this looks too much like a known copyrighted thing." Type 3 is the catch-all wording the same audit step returns when it can't (or won't) name the exact reason.
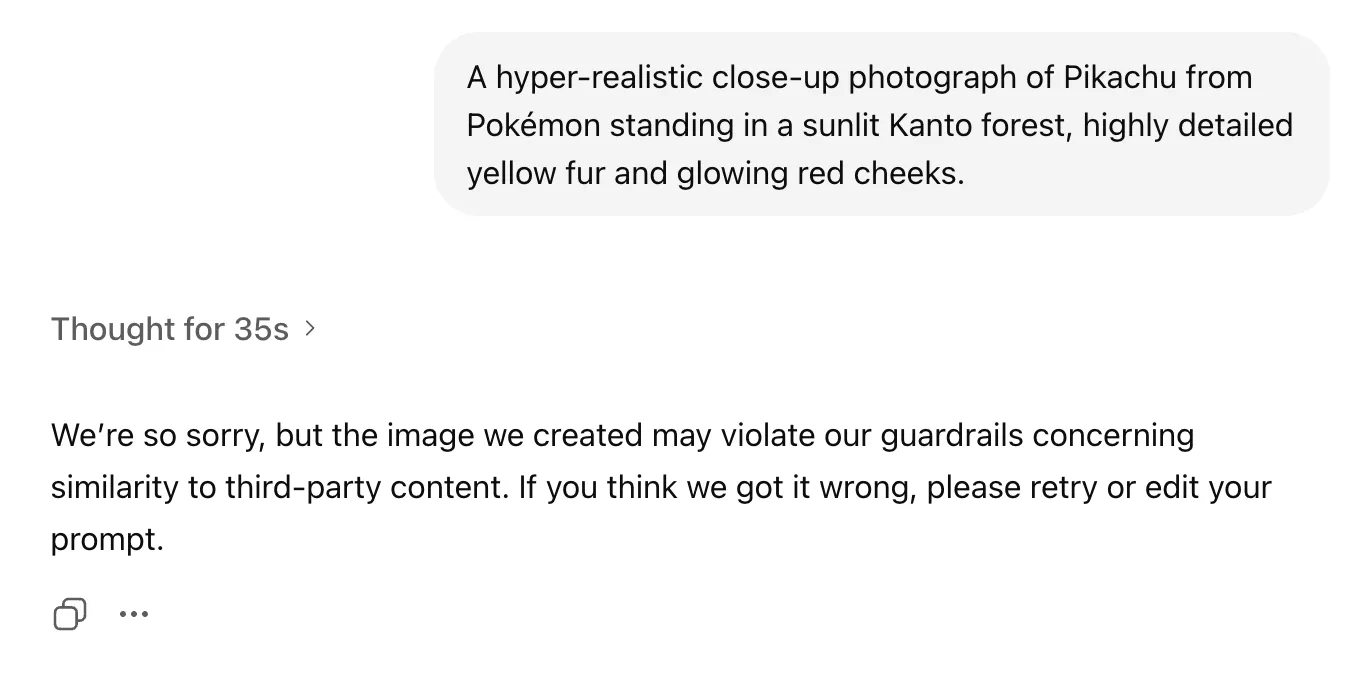
One thing that's easy to miss in the wording: all three messages end with an implicit "try again." They're deliberately non-committal. OpenAI's system doesn't tell you why your image was flagged, only that it was. If you're used to deterministic APIs, this is the first sign that the filter you're up against isn't a simple keyword list — it's a probabilistic classifier sitting at the end of the pipeline.
A refused generation usually doesn't count against your ChatGPT usage quota — the small mercy in all of this. But if you're running the same prompt repeatedly hoping it'll slip through, you're burning your own time playing against a die-roll. The rest of this post is about understanding the die.
How GPT Image 2's two-layer content filter works
GPT Image 2 runs two independent filters on every request: a pre-generation prompt check during the "thinking" phase, and a post-generation image-similarity check on the finished output. A prompt can pass the first and still fail the second — which is why you can watch the model "think" for half a minute before it refuses to hand over the image.
The first layer is the prompt check. GPT Image 2 surfaces its reasoning in a "Thinking" trace before generating, and if you read those traces across many prompts for copyrighted characters, the model's internal policy is remarkably consistent. Here are two real examples pulled from our test runs:
Mario attempt (pre-generation reasoning): "I think creating a new image of a well-known character like Mario could be allowed, as it's not directly copying official artwork. The idea is to depict him in a new scene, with something like a photorealistic, cinematic style. I'll make sure his identity is clear, but without directly copying existing art."
Pikachu attempt (pre-generation reasoning): "I need to respond to the image request for Pikachu, but it's a copyrighted character. The policy is clear about not copying images directly, but I think generating an original image is fine, especially with a specific request like a photorealistic Pikachu in a forest. I'll move forward with that!"
Notice how close these are linguistically. Both attempts are for "well-known copyrighted characters," both explicitly acknowledge the copyright, and both decide the request is acceptable because it's "a new image" rather than "copying existing artwork." That framing isn't accidental — it's the system prompt OpenAI has trained the model on, which draws the policy line at reproduction of specific pieces of art rather than at the existence of a character. Under this rule, nearly any copyrighted character is fair game at the prompt stage, as long as you don't ask for a literal copy of a specific poster, frame, or piece of official art.
So far, so permissive. The problem is that the prompt layer is not the only layer.
After the model finishes generating, the image is passed through a second, independent check: a similarity classifier that compares the finished image against a catalogue of known third-party content. This is where Type 2 and Type 3 blocks come from. The classifier doesn't read your prompt at all — it looks at pixels — and if it decides the generated image is too close to something in the catalogue, it rejects the output and returns the "similarity to third-party content" error.
This two-layer architecture is what produces the apparently weird sequence where the model happily "thinks" for 30+ seconds, generates an image, and then refuses to give it to you. The 35-second wait you see in the Pikachu screenshot above isn't the safety system stalling — it's the model doing the actual drawing. The refusal comes at the very end, when the finished pixels meet the similarity classifier and lose.
There is no client-side switch that turns the similarity audit off. Whether you're accessing GPT Image 2 through ChatGPT or through any other frontend, the check runs inside OpenAI's serving stack, so nothing you do at the prompt or session level changes whether the check fires — only whether the generated pixels happen to trip it.
The two-layer design is also what introduces the randomness you'll notice if you run the same prompt twice. The prompt check is relatively deterministic — a given piece of text either trips the sexual-content filter or it doesn't, and rewordings tend to be stable. The image similarity check is the opposite: it's a classifier operating on generated pixels, and because the model produces slightly different pixels every time (different seed, different noise), the same prompt can yield two generations that sit on opposite sides of the classifier's threshold. That is a significant part of what the next section is about.
Which copyrighted characters get blocked? A 10-IP first-round test
We ran the same prompt template against ten major non-Disney IPs to see which ones GPT Image 2 would refuse. The first-round result: six got blocked, four got through — and the "through" results aren't stable.
Each prompt used the same shape: a photorealistic, cinematic description of a single named character in a signature setting, with the rightsholder mentioned explicitly to maximise the signal for any similarity check. Here are the first-round results:
| # | Rightsholder | Character | First-round result |
|---|---|---|---|
| 1 | Nintendo | Mario | Blocked (Type 2) |
| 2 | The Pokémon Company / Nintendo | Pikachu | Blocked (Type 2) |
| 3 | Warner Bros. / DC | Batman | Blocked (Type 2) |
| 4 | Hasbro | Optimus Prime | Blocked (Type 2) |
| 5 | Universal / Illumination | Minion | Blocked (Type 2) |
| 6 | SEGA | Sonic | Blocked (Type 2) |
| 7 | Toei / Shueisha / Bandai | Goku | Passed |
| 8 | Sanrio | Hello Kitty | Passed |
| 9 | Mojang / Microsoft | Minecraft Steve | Passed |
| 10 | Studio Ghibli | Totoro | Passed |
Before you read anything into the "passed" column: these results are not deterministic. When we re-ran the Goku prompt — the identical string, no changes — it came back as a Type 2 block on the second attempt. Steve, rerun with the identical prompt, still passed. In other words, whether a given IP-plus-prompt combination slips through the similarity classifier is partly a coin flip. Treat this table as "what happened in one run," not as a list of IPs you can reliably use.
Two observations worth pulling out.
Disney is not the special case. The popular theory is that GPT Image 2 treats Disney with unique strictness. Our test doesn't support that. Nintendo, Warner Bros., Hasbro, Universal/Illumination and SEGA were all blocked on the first pass, and none of those are Disney subsidiaries. Whatever is being protected here, it's the whole tier of high-profile commercial IPs, not a Disney-specific list.
Passing doesn't mean "looks nothing like the original." This is the counter-intuitive part.


Both of these images are extremely recognisable. The Hello Kitty image even rendered the words "Hello Kitty" in the background. If you'd shown either of them to the similarity classifier in isolation and asked "is this a protected character?" the answer is obviously yes. They still passed. The correct reading isn't "OpenAI gave Sanrio and Studio Ghibli a pass" — it's that the post-generation classifier has some false-negative rate, and these generations happened to fall into it. A re-run could easily flip the result.
The clearest illustration of that is what happened when we re-ran the test. Goku passed on the first attempt — the image below is that first-run generation. When we ran the identical prompt string a second time, with no rewording, no seed change, no parameter tweaks, it came back as a Type 2 block. Minecraft Steve, tested the same way, passed both attempts. Same audit, different verdict per IP, and for Goku a different verdict per run.


This is what "probabilistic" means in practice. The filter isn't a deterministic allow-list; it's a classifier whose verdict on the same image request can flip between runs. Any table of "which IPs pass" — including the one above — should be read as a single snapshot, not a stable policy.
Why do some IPs slip through and others don't?
The most likely explanation is coverage in the similarity classifier's training data, not editorial favouritism. If the classifier has seen a lot of reference imagery for a given character, it recognises the pattern aggressively; if it's seen less, it misses.
Mario, Pikachu, Batman, Sonic, Minions and Optimus Prime are among the most photographed, merchandised and screenshot-circulated characters in the world. A similarity classifier trained on web-scraped image data will have seen more of them than of almost anything else. The block rate follows the exposure. Goku, Totoro, Hello Kitty and Minecraft Steve aren't obscure — but their canonical visual reference sets are narrower (fewer poses, fewer licensed still frames at scale), and the classifier is correspondingly less confident. That lower confidence shows up as the false-negative rate you see in our test.
There is a separate rumour that Disney's December 2025 $1B investment in OpenAI and three-year licensing agreement for Sora causes Disney characters to be filtered more aggressively as a contractual obligation. It's a narratively tidy theory, but our data doesn't really need it: the block list is already explained by training-data coverage, and the fact that Nintendo, Warner Bros., Hasbro and SEGA are blocked just as hard as any Disney IP makes the "special Disney protection" angle hard to isolate as an independent effect. It's plausibly a small contributor at the margin — this is not a disproof — but it's not the main story.
It's worth putting the Ghibli result in historical context. In March 2025, GPT-4o's new image feature produced a viral wave of Studio Ghibli-style generations that TechCrunch described as a crystallising moment for AI copyright concerns, and Sam Altman publicly acknowledged that ChatGPT's image servers were struggling to keep up. OpenAI followed up by tightening its policy around images in the style of living individual artists, which was widely read as a partial response to the Ghibli situation. Then, in October 2025, OpenAI launched Sora 2 with an opt-out copyright model and reversed course within days to an opt-in model after pressure from the MPA and talent agencies. IP sensitivity isn't a fixed quantity at OpenAI — it moves with public pressure, rightsholder action, and the balance of deals on the table.
None of that fully explains why Totoro passed this one time. It just establishes the surrounding context: OpenAI's rules around named IP have been actively negotiated and re-negotiated throughout 2025, and the thing that feels random at the prompt level is sitting on top of a policy regime that has been anything but stable. Our best read is still that the pass was a false negative from the similarity classifier, not a deliberate carve-out.
What to do when you hit a block
Three things work, in roughly this order: retry, rewrite, or switch models. Which one makes sense depends on which block type you got and how attached you are to the specific IP.
If it was a Type 1 block, retrying won't help. The prompt filter is deterministic on the prompt string, so the same wording will produce the same refusal every time. Your only options are a rewrite (to remove whatever the filter flagged) or a different model — retrying without changing the prompt is wasted time.
Retry first, if it was a Type 2 or Type 3 block. Because the post-generation similarity classifier has meaningful false-positive and false-negative rates, the same prompt run twice doesn't always produce the same verdict. A Totoro prompt that passed today might block tomorrow. A Goku prompt that blocked might pass on the next attempt. This isn't a reliable strategy for production work, but since refused generations don't consume your ChatGPT quota, it costs nothing except time — if you have a specific image in mind and a few minutes to spare, retrying is the cheapest first move.
Rewrite the prompt if retrying stops helping. The two rewrites that most consistently unblock a Type 2 are (a) removing the rightsholder mention ("Pikachu from Pokémon" becomes "a small yellow electric creature with red cheeks") and (b) shifting from a named character to a style or archetype ("Ghibli-inspired forest spirit" rather than "Totoro"). This isn't a workaround document for the nudity filter — Type 1 blocks, the ones that mention "nudity, sexuality, or erotic content," are enforced against the prompt itself, and rewriting them to evade enforcement is a different category of request that we don't cover here. Those sit inside OpenAI's broader adult-content policy, which has its own longer story (see the upcoming post below).
Switch models if you actually need the named character rendered faithfully. Not every image model ships with OpenAI's similarity-audit layer, and for most branded or franchise characters the real fix isn't a cleverer prompt — it's a different model. Chinese-developed models in particular, like Seedream 4.5 and Seedream V5 Lite, are far more permissive about copyrighted subjects and produce comparable results on most prompts at lower cost per image. If you've been hitting Type 2 blocks on the same IP repeatedly, the model is the thing to change, not the prompt. VidCella hosts both Seedream models pay-as-you-go with no ChatGPT subscription required — that's the easiest path off this lottery if you've decided it's not worth playing.
One more thing worth saying explicitly: a block isn't a bill. A refused GPT Image 2 generation typically doesn't consume your ChatGPT quota, and on most pay-as-you-go hosts it doesn't cost credits either. The only thing a block actually costs you is the time the generation took. Read it as a signal — retry, rewrite, or switch tool — not as a loss.
Coming next: OpenAI's adult-content policy
Type 1 — the "nudity, sexuality, or erotic content" block — sits on top of a longer policy story we're not going to unpack in this post. Sam Altman has publicly talked about "treating adults as adults" for years, OpenAI's own safeguards around image generation have been tightened and loosened multiple times through 2025, and the current 2026 enforcement behaviour — what you see when you hit the Type 1 message today — is the tail end of a multi-year oscillation between permissiveness and restriction.
Our follow-up post on OpenAI's adult-content policy traces that arc end to end: what OpenAI originally said about adult content, what actually shipped (teen protections, age prediction), what got paused (Adult Mode itself, on March 26, 2026), and what the current policy means in practice — inside ChatGPT or otherwise. If Type 1 blocks are the reason you're reading this, that's the follow-up you'll actually want.
Still getting blocked? Try a model without the guardrails.
VidCella hosts Seedream 4.5, Seedream V5 Lite, Wan 2.5 Image and more — pay-as-you-go, no subscription, and no “similarity to third-party content” wall.
Failed generations don't cost credits · No ChatGPT Plus required